Deploy
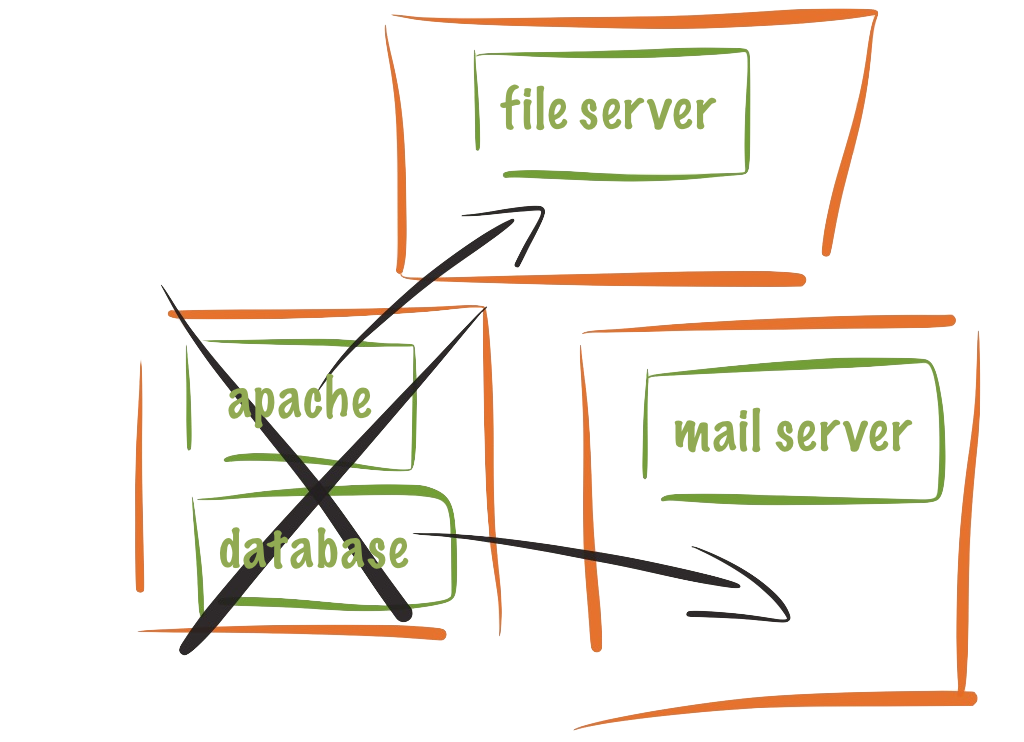
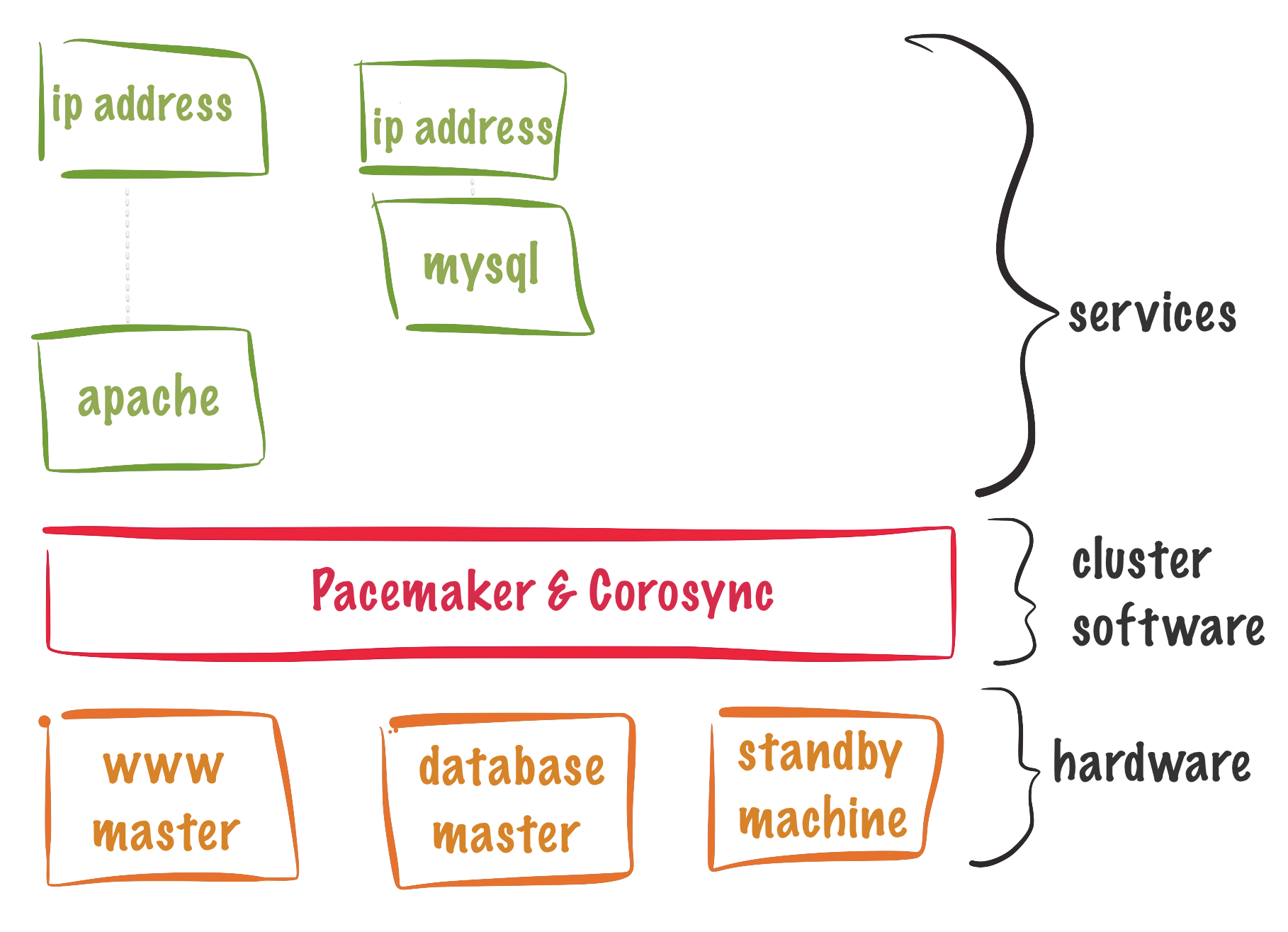
We support many deployment scenarios, from the simplest 2-node standby cluster to a 32-node active/active configuration. We can also dramatically reduce hardware costs by allowing several active/passive clusters to be combined and share a common backup node.